Executive Summary
Amazon SageMaker AI now enables serverless fine-tuning of foundation models like Qwen 2.5 7B using Reinforcement Learning with Verifiable Rewards (RLVR). This approach reduced tool call failures by optimizing decision-making behaviors and simplifying operational overhead.
Technical Breakdown
Introduction to RLVR in SageMaker
Reinforcement Learning with Verifiable Rewards (RLVR) is designed to refine models for decision-making tasks where behaviors are naturally verifiable. For tool calling, RLVR solves issues like incorrect API invocation, hallucinated tools, or missing clarification requests by using structured reward signals.
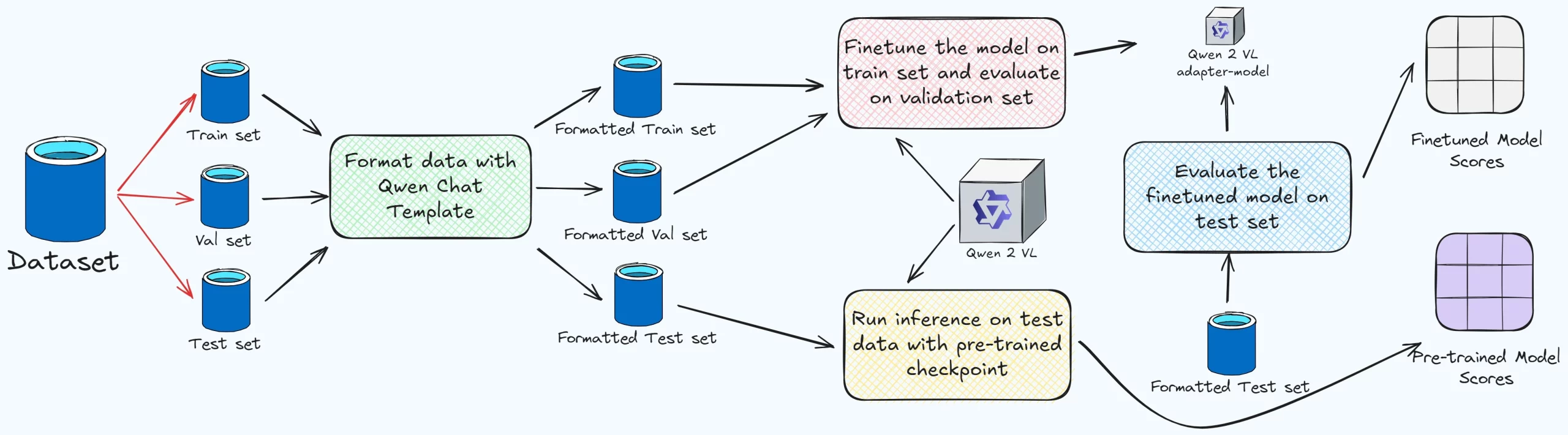
Dataset Preparation
Training data was synthetically generated to cover three agentic behaviors for tool calling:
Execution (60%): User request includes full parameters.
Clarification (25%): Missing or ambiguous parameters.
Refusal (15%): Harmful or out-of-scope requests.
Dataset format (JSONL):
{"prompt": [{"role": "system", "content": "You are an intelligent assistant..."}, {"role": "user", "content": "get_weather_forecast for San Francisco."}], "reward_model": {"ground_truth": {"tool_call": {"name": "get_weather_forecast", "parameters": {"location": "San Francisco"}}}}}
This dataset ensures realistic input diversity across varying phrasings and tool schemas.
Reward Function Design
The reward function scores responses across three tiers:
1.0: Correct tool call with all parameters.
0.5: Missing or incorrect parameters.
0.0: Incorrect tool call or unnecessary actions.
Python-based reward logic:
def reward_function(response, ground_truth): try: tool_call = json.loads(response["tool_call"]) if tool_call == ground_truth["tool_call"]: return 1.0 elif tool_call["name"] == ground_truth["tool_call"]["name"]: return 0.5 else: return 0.0 except: return 0.0
This ensures both precision and flexibility, supporting natural language outputs for clarification/refusal cases.
GRPO Training Configuration
Using Group Relative Policy Optimization (GRPO), RLVR was configured with the following hyperparameters:
Batch size: 128
Learning rate: 5e-6
Epochs: 3
Rollouts per prompt: 8
During each prompt rollout, eight candidate responses are sampled and scored by the reward function. Responses scoring above the average reinforce model policy updates. Training and evaluation metrics were tracked via MLflow.
Validation and Deployment
Models fine-tuned on the training set were evaluated using held-out prompts with unseen tools. Deployment leveraged SageMaker’s serverless architecture, simplifying retrieval, hosting, and scaling efforts.
Benchmark Analysis
Model
Tool Call Reward Increase
Held-Out Prompt Accuracy
Base Qwen 2.5 7B
65%
Fine-tuned Qwen (RLVR)
+57%
86%
Architecture Notes
Deployment used serverless hosting via SageMaker, supporting autoscaling for inference while offloading checkpoint management and GPU workloads. Modular integration supports reward refinement without retraining full models.
Why It Matters
Tool calling reliability is critical for production AI workflows. RLVR significantly boosts model accuracy without requiring costly operations, enabling scalable, high-confidence agent deployments in environments like customer support or enterprise automation.
Open Questions
How does performance scale on larger prompts or complex tool schemas?
Does RLVR introduce biases in multi-tool environments?
What are the trade-offs between RLVR and preference-based optimization methods (e.g., DPO)?
Source & Attribution
Original article: Accelerate agentic tool calling with serverless model customization in Amazon SageMaker AI
Publisher: AWS Machine Learning Blog
This analysis was prepared by NowBind AI from the original article and links back to the primary source.